The ALADIN project aims to build an integrated and distributed technological platform which will rely on the combination of combinatory genetics with artificial intelligence. It will enable the exploration of natural molecular diversity, its appropriation to build new purpose-based catalysts (enzymes and micro-organisms), and the rapid expansion of the knowledge base necessary to better understand biological systems. As a result, it will accelerate and increase probability of success of bio-based transformation process development along 3 majors features:
– Accelerating the catalyst development pipeline through automated high throughput gene identification, high throughput enzyme activity screening and miniaturization of strain engineering to build more strains at a lower cost and in a shorter time.
– Collecting on-line real time data with advanced analytics to address heterogeneity issues, which arise during scale-up and production, and trigger proactively corrective actions through quantitative measurement of cell population heterogeneity, early detection of transgene integration and genetic instability.
– Capitalizing on the wealth of data generated during the screening and development phases using advanced learning.
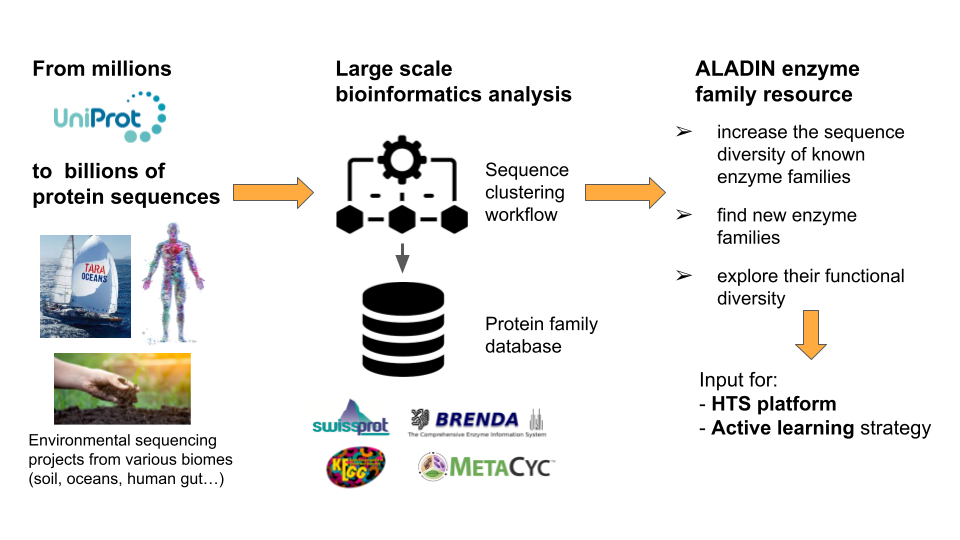
As part of this collaborative project, the LABGeM will provide a bioinformatics workflow to explore the functional diversity of enzyme families from metagenomic data. From these enzyme families, structure- and sequence-based methodologies will be performed to finally select interesting families for high-throughput screening.
This project is funded by the ANR ESR-Equipex+ (reference IA-21-ESRE-0021)
Keywords: Active learning – Biocatalysts – Bioprocessing – Genetic Engineering – Industrial Biotechnologies – Bioproduction – Bioeconomy